

Fig. 1
In order to reduce the expenses of hosting fine-tuned LLMs in production and face key challenges like high computational requirements, storage needs, inference latency, and scalable AI hosting, organisations can implement various strategies.
Resource Provisioning
Resource provisioning can either be static or dynamic. Tools like AWS, EC2, Spot Instances, or Google Cloud Preemptible can be used for hosting. These are popular options as they offer significant cost savings over on-demand instances, which makes them ideal for low-cost machine learning hosting and LLM hosting solutions.
While there is a risk of interruptions while using these tools, the fault-tolerant architecture provided by these VMs can mitigate these risks and ensure continuous availability, providing a robust environment for LLMs in production.
Moreover, applications are monitored by AWS auto-scaling so that capacity can be changed on demand, safeguarding resource performance while meeting price expectations.
Model Pruning and Quantization
Model pruning and quantization are techniques used to constrain and advance deep learning models.
Quantization involves reducing the precision of the weight and activations in a model, typically from 32-bit floating point values to 8-bit integers.
Pruning means removing unnecessary connections from the language model. Pruning can be done during either training or fine-tuning LLMs in production.
These revised language models are faster and cheaper, as less memory and computer power are needed. However, they still achieve acceptable levels of accuracy.
Caching and Memorization
A caching mechanism can be used to store frequently accessed data. This reduces the need for unnecessary computations and improves inference latency.
The memorization technique is used to remember previous interactions (like those used by ChatGPT) and enables quicker response generation for repetitive queries and inputs.
Inference Optimization
The basic idea of inference optimisation is to use cheaper processes to generate the best models. This is achieved through many techniques, such as batch processing, parallelisation, asynchronous inference, and hardware accelerators.
Organisations aim to achieve model inference optimisation by:
- Downloading the latest versions of PyTorch, Nvidia Drivers, etc., and upgrading to the latest compatible releases.
- Collecting system level activity logs to understand the overall resource utilisations.
- Improving targets with the highest impact on performance.
Dynamic Resource Allocation
Dynamic resource allocation includes methods like monitoring and scaling, autoscaling, and resource pooling. These methods dynamically allocate resources based on demand fluctuations, reducing host costs while maintaining performance. This approach ensures efficient resource use and minimizes idle capacity.
Let us understand the implementation of the strategies by taking the example of a hypothetical company that uses these strategies to efficiently deploy and manage fine-tuned LLMs in production for a customer support chatbot.
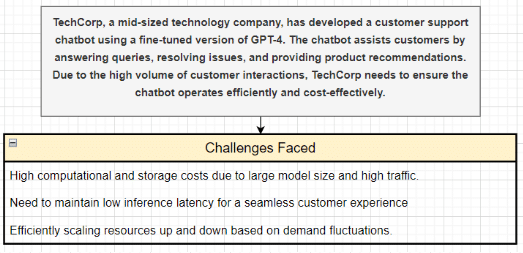
Fig. 2
Let us assume that in the year 2024, TechCorp (the hypothetical company) was worried about putting support chatbots on its website. The reason for the hesitation and worry was the high costs and challenges of hosting FineTuned LLMs in production.
Let us now see how they implemented the strategies that we discussed in the previous section.
Resource Provisioning
TechCorp designed a fault-tolerant architecture using tools like Kubernetes for container orchestration. This was to use spot instances or preemptible VMs.
Kubernetes was used to manage the deployment, scaling, and operations of the chatbot containers across a cluster of devices.
Auto-scaling groups were configured to automatically adjust the number of requests received based on current demand. This ensured that resources were scaled up during peak hours and scaled-down during off-peak times, ensuring cost efficiency.
Critical data used for user interactions and model outputs were persisted in tools like Amazon S3. This ensured that even if spot instances were interrupted, data security and integrity could be maintained while significantly reducing computing costs.
Model Pruning and Quantization
TechCorp used the TensorFlow Model Optimization Toolkit to prune and quantize the fine-tuned LLMs in production. This strategy helped TechCorp by supporting affordable AI infrastructure and efficient LLM deployment.
The pruned and quantized model can be fine-tuned again to recover any loss in accuracy. Thus, TechCorp solidifies its position as a leader in AI hosting solutions.
Caching and Memorization
TechCorp implemented caching layers for LLMs in production using no SQL tools like Redis to store frequently accessed data.
This approach uses Redis to cache common queries and their responses. This allows the chatbot to quickly retrieve and serve queries without recomputing them, ensuring optimized AI deployment.
Minimizing redundant computations can significantly reduce processing overhead and improve the chatbot’s response time.
Inference Optimization
TechCorp optimised the inference pipeline 200 batch processing and parallelization, ensuring cost-effective AI hosting.
Experiments with various batch sizes of frequently accessed data and concurrency levels help to determine the most effective configuration.
Striking a balance between throughput and latency ensures the chatbot can handle high volumes and provide fast responses while minimizing resource usage.
Dynamic Resource Allocation
TechCorp set up comprehensive monitoring and dynamic resource allocation strategies using tools like Prometheus and Grafana.
Grafana is used to visualize system metrics like CPU utilization and memory consumption and monitors request rates to identify trends.
Further, based on real-time metrics, an auto-scaling policy can be implemented to adjust resource allocation.
Using AWS Auto Scaling and Google Cloud’s Managed Instance Groups ensures that resources are allocated efficiently in response to demand fluctuations.
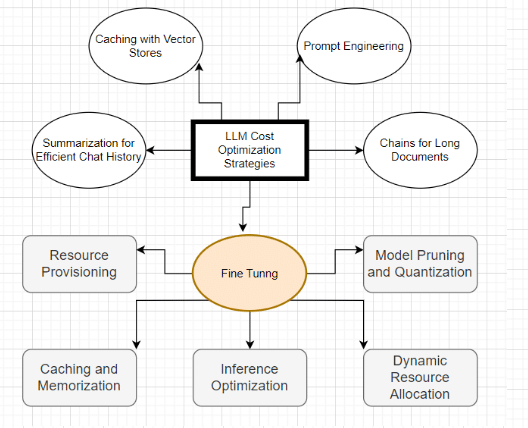
Fig. 3

